Recently, we built Fresh Web Explorer a large scale feed crawler and search engine that allows inbound marketers to do all sorts of wonderful marketing related things. Dan has already written about some of the technical details and the overall architecture, and this post about Feed Authority is the first in a series of deep dives about the individual components. Future posts will describe our crawler and de-chroming/content extraction algorithm.
Feed Authority measures the influence of any individual feed and is used to separate important from un-important feeds. It is a prominent, customer facing metric and so must “make sense” to customers (e.g. we can’t return a score of -23.55). We also plan to use it internally in our schedulers to prioritize higher quality feeds in the crawlers.
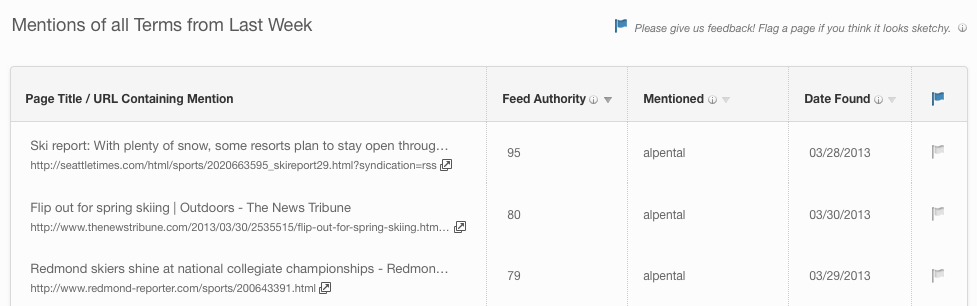
After starting this project, we quickly realized that most feeds on the Internet, relatively speaking, are things like:
- alternate format feeds that contain the same content (e.g. xml vs atom)
- feeds for each individual category or tag for a blog
- comment feeds for individual blog post
- Facebook page feeds — every Facebook page has an RSS feed (!)
In fact, we even found a clever service that makes it easy to create a feed that is a combination of other feeds (Yahoo Pipes).
This makes it somewhat difficult to define a measure of importance since it muddles the intuitive notion of a important content being associated with a important quality feed (e.g. a comment feed on a popular blog). In the end, we decided to use the number of subscribers to the feed itself as our measure of importance.
Machine Learning Approach
At our scale, we didn’t want to rely on a third party API to provide subscriber counts so instead we used a supervised machine learning approach. We first took a representative sample of feeds and collected the subscriber numbers from a popular feed reader. Then we used standard machine learning techniques to fit a regression model following best practices. We randomly split the data into training/test sets and used 5-fold cross-validation to select features to include in the final model, determine the final model structure and set the regularization parameter.
Model Features
To use Feed Authority as a filter in crawl schedule, we need to be able to compute it after fetching the feed, and before crawling any of the links on the feed. We also want to minimize the amount of stored data needed to compute the score. Finally, the calculation needs to be efficient.
Accordingly, we restricted the model features to those we can extract from the feed itself, as well as link metrics from our Mozscape index. These features can all be computed efficiently and are bundled together into a JSON blob that is input into the model.
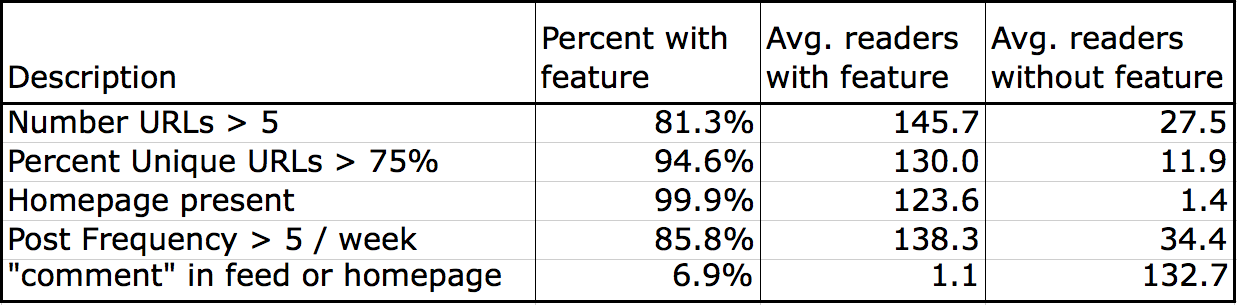
Through trial and error, we have found a set of features in the feed with good predictive power. The above table illustrates a few of them. In the table, we have calculated the percent of our training data with a particular feature, and then computed the average number of subscribers for feed with and without the feature. For example, the top row shows that approximately 80% of the feeds have more then five links, and those feeds have about 5X the number of subscribers. We extract additional features that measure the number of unique URLs on the feed (after certain normalizations) and post frequency. Due to the prevalence of popular content management systems like WordPress, we can also take advantage of obvious patterns in the feed URLs themselves. For example, many comment feeds include the string “comment” in the feed. The bottom row of the table shows that these are about 7% of the training data, and account for more then 100X difference in readership.
One important piece of meta data that most feeds include is a link to the “homepage” of the feed. The middle row of the table shows that nearly all feeds include such a link (and for the tiny fraction that do not, the subscriber counts are very low). We extract this URL then query the Mozscape API for the associated link metrics, including Page and Domain Authority. We also pull the link metrics for the feed URL itself and include them in the model.
Modeling approach
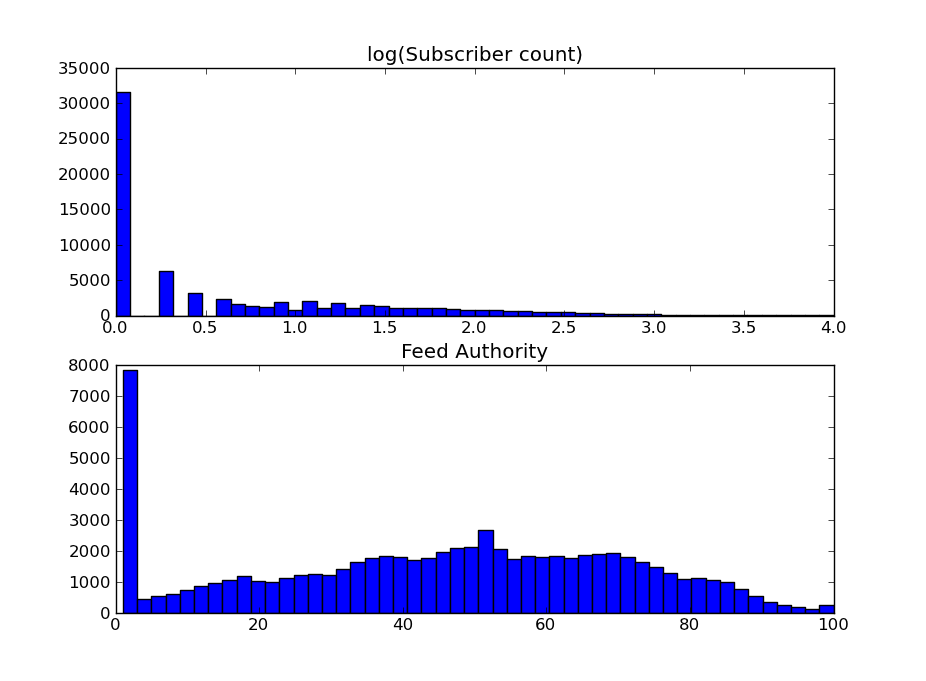
The top panel of the chart below shows a histogram of log(subscriber count) for our training data. Many regression techniques like linear regression or neural networks assume the data is Gaussian, but it’s clear our data isn’t. We experimented with several different models and eventually found negative binomial regression to work the best.
Rescaling
The final step in calculating the final Feed Authority score involves rescaling the raw model output to the familiar 1-100 scale, consistent with our other Authority scores (Page/Domain and the newly released Social Authority). We also apply some additional consistency checks at this point to ensure that the final score is broadly consistent with Domain Authority. The bottom panel of the chart plots the distribution of the final Feed Authority score across our training sample. Overall the average score is about 45 with 11% of the feeds having Feed Authority less then 2.0.
Acknowledgements
Like all projects at SEOmoz, Feed Authority was a team effort. In particular, Dan Lecocq wrote the feed parser and feature extractor. Jerry Feng updated the first version of the model and implemented the negative binomial regression. Samantha Britney and Matthew Brown provided valuable feedback and guidance from the product side.
Note: this article was originally published on the Moz devblog.
Update Fall 2015
Due in part to the issues highlighted above, we replaced Feed Authority with “Mention Authority” in 2014. Our motivation was:
- It is more useful to measure the importance of the page with the brand mention (Mention Authority) then the feed where the post was discovered (Feed Authority).
- Some pages are in included in multiple feeds with different Feed Authority so the mapping from feed to page is not 1:1. For example the same page might be included on the blog homepage feed, each category tag feed, and the post comment feed.
- We can more reliably estimate Mention Authority then Feed Authority.
We calculate the Mention Authority of a page by blending together two proxies for influence:
- The Domain Authority of the site. Large domains with many inlinks are more important.
- and the Social Authority of any social accounts we discover on the page. Pages associated with influencial Twitter accounts are likely to be more influencial.