Recently, we have been working to improve Dragnet, Moz’s content extraction algorithms. These algorithms analyze a web page and separate the main article content (optionally with user-generated comments) from the navigation “chrome” (sidebars, footers, copyright notices, etc). Along the way, we benchmarked Dragnet against a few other Python content extraction repositories in execution speed and accuracy. This post describes those benchmarks and our journey to extend the original Dragnet algorithm.
Dragnet is available on PyPI: check out this page for installation instructions.
Our Data Use Cases
Throughout this post we will address two different use cases:
- Task 1: Extract the main content and all comments
- Task 2: Extract just the main article content, ignoring any comments
Our primary data source is the test set from our 2013 paper, Content Extraction Using Diverse Feature Sets, collected in late 2012. It consists of 414 blog posts and news articles from a wide variety of sites (see the paper for details). In addition to the main article content, the gold standard also contains any user-generated comments, so it allows us to benchmark algorithms on both use cases above. This test set, as well as an additional 965 page training data set, is available at Dragnet Data. Since we trained the Dragnet models on the training data, we focus on performance on the out-of-sample test set in this post.
Note: We also benchmarked against older data sets (namely the “Big 5” dataset from 2009 and CleanEval-EN from 2007), with similar results. Since this post is already packed, we’ve left those results for a future post.
For example, here is a sample blog post with four comments from the 2012 dataset:
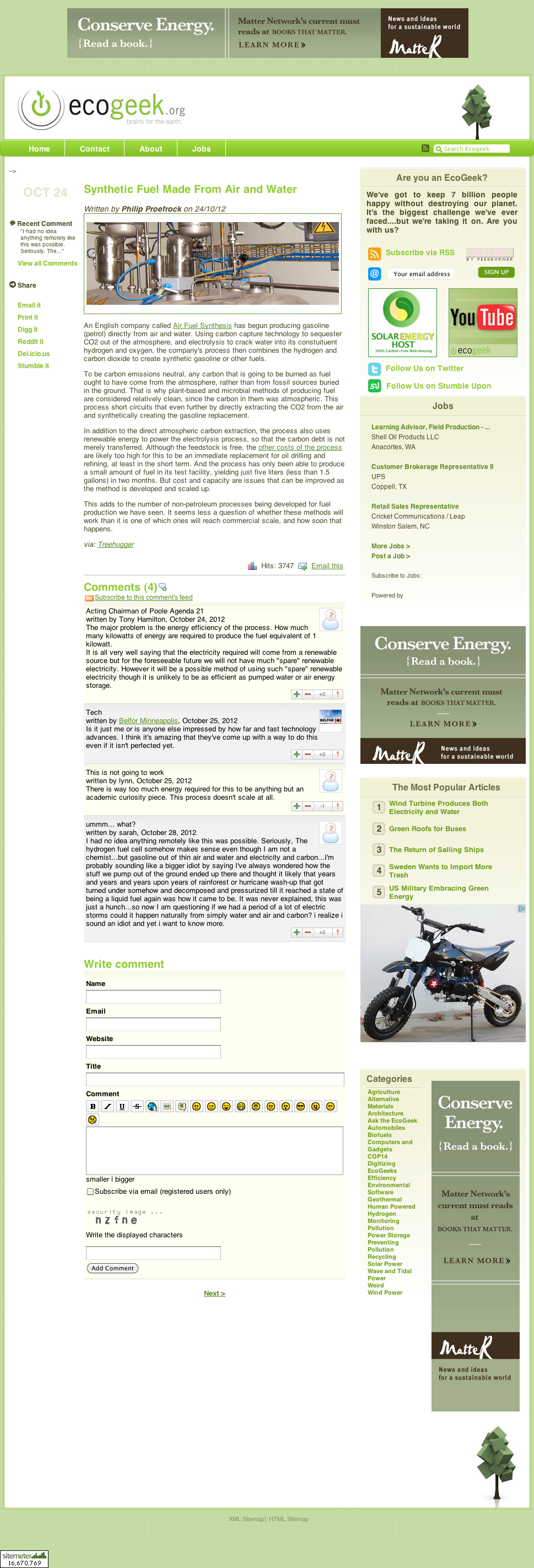
Determining Main article Content vs Comments
The original Dragnet algorithm in the 2013 paper was designed to extract both the main content and user comments, as required by product uses internally at Moz (Task 1). At a high level, it works by (see this older post for more details about the algorithm):
- Splitting a web page into a sequence of “blocks”
- Extracting a set of features for each block
- Running a machine learning model to decide which blocks are content and which are chrome
These “blocks” are individual page chunks separated by HTML tags used for visual
markup like <div>, <p>, <h1>, etc. For example, here is the block
representation of the sample post above:

Even without reading the tiny font, you can likely pick out the main content in the block representation based on the amount of text and links. Indeed, these are the most important features in Dragnet.
Blocks with high text density and low link density are most likely to be the main content.
Anecdotally, we noticed that the original Dragnet algorithm sometimes confused short text sections, like copyrights and related article snippets at the end of pages as content, while passing over comments. I guessed that this was because comments looked more like chrome than article content as represented by our model features, since comments tend to be shorter then content. Accordingly, when it became necessary to also produce a content-only extraction model (Task 2), I thought that simply retraining the original Dragnet algorithm while excluding comments from the gold standard would be sufficient. If comments and contents have systematically different distributions of features, then the content-only model might even provide an accuracy boost over the content and comments model.
I was wrong. As viewed by our model features, it turns out that comments look much more like article content than chrome. As an example, the fourth comment in the above post is a similar length to the paragraphs in the main article, and doesn’t contain any links. Any model whose most discriminative features are text and link density will have a hard to impossible time separating it from the main article.
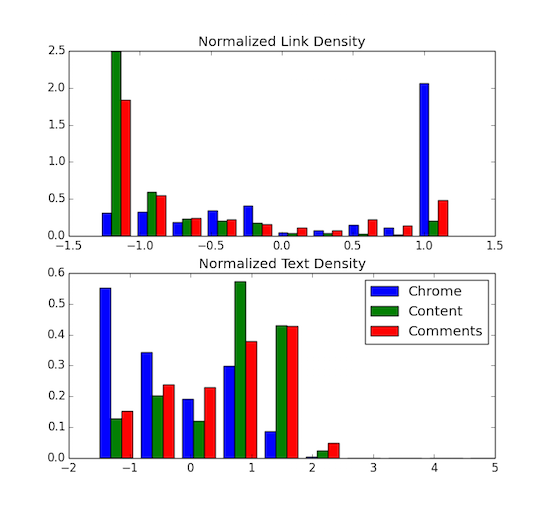
As further illustration of the similarity between main content and comments, the following image plots histograms of block text density and block link density segmented by their labels in the gold standard. The content and comment distributions (green and red bars) are more similar to each other than they are to the chrome distribution (blue bars).
Benchmarking
At this point, we decided to check out other algorithms to see if they have the same behavior. The Python ports of Readability and Goose, as well as Eatiht, are three popular options.
The following table compares the token-level performance and speed of Task 1 (content and comments extraction). From left to right, it lists the precision (percentage of all tokens extracted that actual content/comments), recall (percentage of all gold standard tokens actually extracted), F1 score (harmonic mean of precision and recall) and speed (number of pages per second). The “Dragnet v1” row is the highest performing model in our 2013 paper, with the bottom Dragnet model to be described shortly.
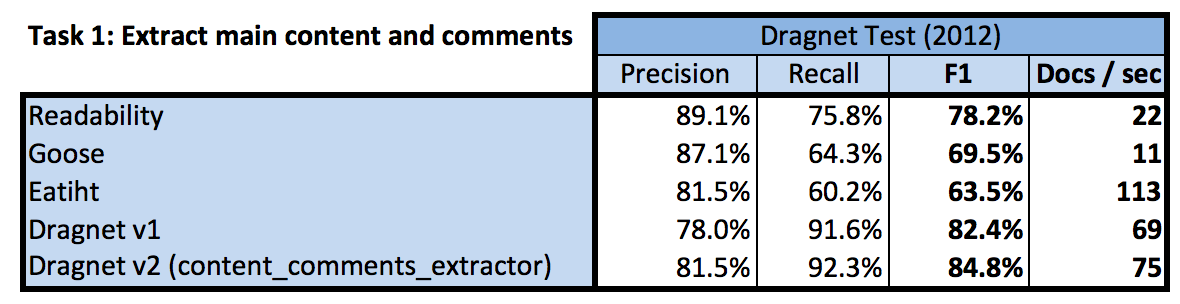
Overall, the Dragnet model is significantly faster than Readability and Goose and has a higher F1 score than the other algorithms at this task.
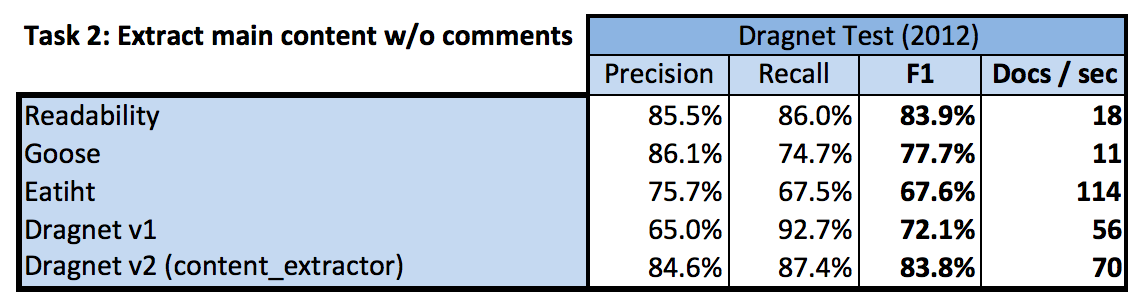
Now we turn to Task 2 in the following table (content only/no comments). Compared to Readability and Goose, the Dragnet v1 algorithm has a substantially lower F1 score, due to the low precision. The Eatiht algorithm is far and away the fastest implementation, but lags in accuracy.
Improving Dragnet with Readability
Readability’s F1 score in Task 2 on the 2012 test set is impressive so we set out to see if we could improve Dragnet using some of its salient features.
At a high level, the Readability algorithm works as follows:
- Create a parse tree from the document and clean it (remove certain tags and do a filtering step using a blacklist of id/class attributes)
- Iterate through the tree and score all subtrees based on:
- The parent id/class attributes
- The length of text in the subtree
- Some additional heuristics
- Find the subtree with highest score and expand it to siblings using some heuristics
- Sanitize the final extracted content based on some heuristics
While the algorithm contains a long list of hard-coded rules in several places, the core difference from Dragnet is the search for a single subtree, with perhaps some additional siblings. Since it uses document-level features, it is a fundamentally different approach from Dragnet, that uses only the local features of each block.
Document-level wide features relating entire subtrees are powerful predictors of content blocks.
To illustrate the difference, the following figure shows the tree representation of our running example:

In the case of the example blog post, the main article content and comments are found in different subtrees. By restricting the search to a single subtree, the Readability algorithm can use this information to effectively separate the main article content from the comments.
To incorporate these ideas into an improved Dragnet model, we stripped the Readability algorithm to its core and added an additional feature to the Dragnet models as follows:
- Compute a simplified version of the Readability content score for all subtrees in the document. This simplified score uses just the id/class attributes of the parents and the block text length.
- Find the subtree with the highest simplified score in the document.
- For each block, find the maximum score of all subtrees containing the block.
- Finally, compute a block level feature with the ratio of this block level maximum score to the document maximum score.
The bottom row in Table 1 above shows the performance for a Dragnet model including the Readability feature trained for Task 1. Performance improves slightly over the v1 model, but since the main content and comments are often in separate subtrees, performance doesn’t improve significantly.
On the other hand, adding the Readability feature to a model trained for Task 2 improves the F1 score significantly, and it is on par with the full Readability algorithm. However, since our Readability-inspired feature is a major simplification of the full algorithm, the additional features in Dragnet are necessary to improve the performance to that of the full algorithm. We regard this as a conceptual and practical improvement since it doesn’t rely on a long list of hand coded heuristics.
tl;dr: The recently-improved Dragnet algorithms have higher F1 score than other similar algorithms, and are 3 to 7 times faster than Readability and Goose.
Conclusions
Our main takeaways from this short project are:
- The Dragnet algorithms compare favorably against other Python packages both in speed and skill.
- Document wide features – in particular the tree structure as exploited by Readability and the improved Dragnet models – are powerful features for separating main article content and comments.
Note: this article was originally published on the Moz devblog.