With thanks to Rutu Mulkar, Erin Renshaw, Chris Whitten, Jay Leary and many others!
Introduction
Keyword extraction is an important task for summarizing documents and in this post I’ll explain some of the details and design decisions underlying Moz’s keyword extraction algorithm. Our scalable implementation processes a web page and returns a list of keyword phrases with relevance scores. It blends traditional natural language processing techniques with a machine learning ranking model applied to the web domain. (The machine learning pipeline has been in production in Moz Content and Moz Pro for more than a year and has proven to be robust and stable.)
At Moz, we have numerous product uses for a keyword extraction algorithm. For example, we can use a keyword extraction algorithm to tag and summarize a page with the most salient topics or to build a relationship graph between keywords. For example, by looking at which topics co-occur frequently with “event driven programming” we can find related topics (e.g., “node js”). Moz Pro currently includes a feature based on this idea.
Product requirements, problem formulation and alternate approaches
There are many different approaches to topic extraction and summarization. In our case, we want granular, easily interpretable topics that can be computed efficiently.
Latent Dirichlet Allocation (LDA) is a well-known topic-extraction algorithm that defines a topic as a probability distribution over a vocabulary. As a result, its topics can sometimes be difficult to interpret and it tends to extract broad topics (e.g. “computer science” instead of “in-memory databases” or “event driven programming”).
In addition, we don’t want to restrict our extracted topics to a predefined vocabulary. Ideally, we’d be able to capture infrequently occurring phrases such as names or places and be able to extract important keywords like “Brexit” from web pages even if the algorithm has never seen the token before.
To overcome these issues and align with product goals, we decided to restrict our extracted “topics” to be “keyword phrases that occur on the page.” Assuming the keyword phrases we extract from the page are meaningful (e.g. “event driven programming,” not “instead of a”) this approach simultaneously solves the interpretability and out-of vocabulary problems.
Our approach to keyword extraction
Key-phrase extraction has been well studied in the research literature (see Hasan and Ng, 2014, for a recent review). Many of these studies are domain specific (e.g. keyword extraction from a technical paper, news article, etc.) and use small datasets with only hundreds of labeled examples. For example, Table 1 in Hasan and Ng (2014) lists 13 datasets used in prior studies, only four of which have more then 1,000 documents. The size of the datasets has mostly prevented researchers from building complex supervised models, and many of the published methods are purely unsupervised (with a few exceptions including Dunietz and Gillick, 2014, and Gamon et al, 2013). Additionally, since the notion of a “relevant keyword” is not well defined, collecting labeled data can be difficult and result in noisy labels with a small amount of inter-annotator agreement.
Accordingly, we made two design decisions at the project outset. First, we decided to build a task specific method instead of a general purpose keyword extraction algorithm. This simplified the problem and focused our efforts. Second, to collect training data we decided to avoid the complexity of manually labeling examples. Instead, we devised a way to collect a lot of data in an automatic way. This allowed us to build a complex model with many different types of features.
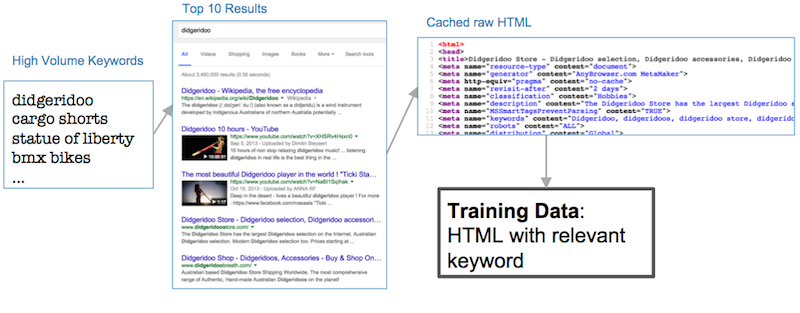
To build the labeled data we…
- Selected a large number of high volume search queries
- Ran the queries through a web search engine and collected the top ten results for each query
- Fetched the web pages from all search results and cached the raw HTML
- Combined the raw HTML with the search query to make pairs (HTML, relevant keyword)
This resulted in a large data set of page-keyword pairs we used to train our machine learning model. We used search volume as a proxy for prevalence on the web so that we had some assurance that the search engine had a large number of pages to choose from when returning the top ten results (and they were therefore highly relevant to the seed query).
Algorithm details
Below you’ll find an illustration of our algorithm. At a high level it extracts keywords from a web page through a two-step process. First, it generates a long list of potential candidates from the page. Then, it uses a machine learning ranking model to rank the candidates by relevance and assign a relevance score.
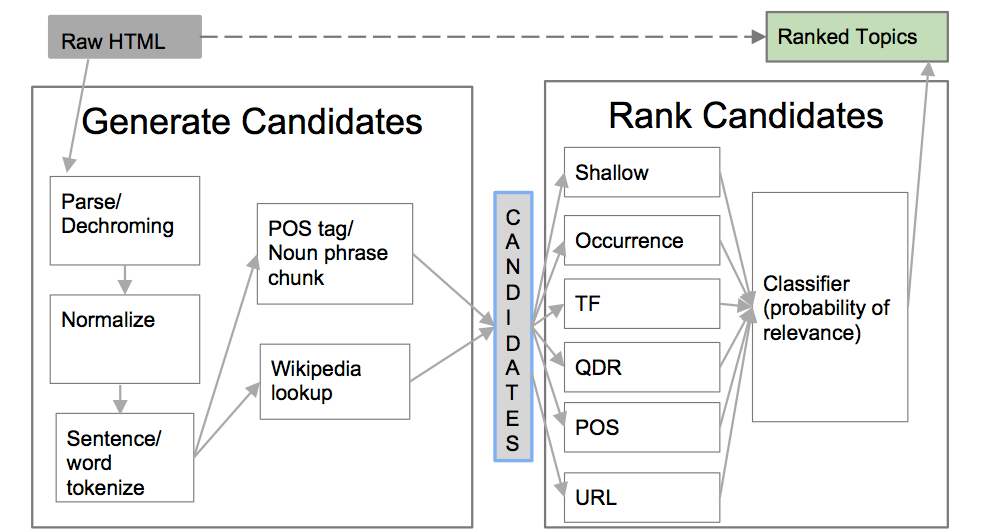
Generating candidate phrases
To generate candidate keywords from the raw HTML, we first parse and dechrome the page (extract the main page content) using Dragnet, our content extraction algorithm. This is important to eliminating most of the text on the page that is irrelevant to the important topics (navigation links, copyright disclaimers, etc.). We also extract some additional structured information at this point: the title tag, the meta description tag, and H1/H2 tags.
Then, we normalize and tokenize the text. Since much of the text on the web is non-standard and most pages include tokens like URLs and email addresses we took care to treat these as single tokens in the tokenizers.
From the tokenized page content, we generate candidates in two ways. The first runs a part-of-speech tagger and noun-phrase chunker on the text and adds all noun-phrases to the candidate list (following Barker and Cornacchia, 2000). Limiting the candidates to noun phrases significantly reduces the set of candidates, while ensuring that the candidates are meaningful.
The second method to generate candidates looks up potential phrases in a modified version of Wikipedia article titles to find important entities that the noun-phrase chunker missed. For example, our noun-phrase chunker will split “Statue of Liberty” into two different candidates, but this step will add it as a candidate.
Relevance ranking model
All of the candidates are passed to a machine learning ranking model that ranks them by relevance. Since we have a large dataset, we were able to include a wide variety of features in the model. They include:
- Shallow: relative position in document, number of tokens, etc.
- Occurrence: does the candidate occur in title, H1, meta description, etc.
- Term frequency: count of occurrences, average token count in the candidate, etc.
- QDR: information retrieval motivated “query-document relevance” ranking signals including TF-IDF (term frequency X inverse document frequency), probabilistic approaches, and language models. We used our open source library, qdr, to compute these scores
- POS tags: is the keyword a proper noun, etc.?
- URL features: does the keyword appear in the URL, etc.?
Since our data set consists of just a single relevant keyword for each page and many unlabeled candidates (some of which are relevant and many of which are not), we could not simply take an off the shelf classifier and use it. Instead, we took a tip from the literature on PU learning. This is an unfortunately named, but interesting and useful subset of machine learning where one is presented with only Positive and Unlabeled data (PU). Among the established approaches to solving PU problems, we chose the one in Learning classifiers from only positive and unlabeled data, Elkan and Noto, 2008. To apply it to our data, we labeled each relevant keyword as positive and all unlabeled ones as negative then trained a binary classifier. The resulting model predicts the probability that each keyword is relevant and ranks the candidates by the predicted probability. A re-scaled version of the model probability serves as our relevance score.
The future
The current algorithm was developed in early 2015 has been in production for more than a year. It has proven to be robust and reliable, but it could be improved in a few ways.
- Most of the errors in extracted keywords are due to errors from the noun-phrase chunker when it extracts a phrase that is not meaningful. NLP technologies move quickly and there have been two high quality open source parsers released since we developed our algorithm (Parsey McParseface and spaCy). If we were to start this project today, we’d likely choose one of these instead of our homegrown one (mltk).
- The second area for improvement is in grouping related keywords. For example, when we run our algorithm on this TechCrunch article about people.ai, both “machine learning” and “machine learning algorithms” are extracted as key phrases. However, these could be grouped together adding more diversity to the top ranked keywords. We currently do some grouping of related keywords but it could be more aggressive.
In lieu of iterations on the current algorithm, we are currently focusing efforts on building a “Topic Reach” that learns topic-site authority associations. We have collected several large search indices internally that provide ideal data sets to analyze.
Note: this article was originally published on the Moz devblog.