Extract a list of author names (or an empty list if no authors) from a given web page.
Moz Content is a tool that analyzes news articles, blog posts and other content to help marketers audit and discover relevant content. To build out that audit feature, we needed a reliable author detection algorithm that could process a web page and return a list of authors. An author detection algorithm is essential to both analyze multiple author sites and track individual authors across multiple sites. This post illustrates our author detection algorithm and provides some benchmarks against Alchemy API and other implementations.
Difficulties of author extraction
When we first started discussing this project, we asked whether we needed to develop a machine learning algorithm or whether a rule-based system would be sufficient. Our product manager, Jay Leary, prototyped a rule-based system that was used in our alpha release. It used these heuristics, among others:
- The microformat
rel="author"attribute in link tags (a) is commonly used to specify the page author. - Some sites specify page authors with a meta author tag.
- Many sites use names like “author” or “byline” for
classattributes in their CSS.
For example, here is a snippet of text from a Seattle Times article that illustrates many of these:
<div class="article-byline">
<div class="name vcard">
By <a href="/author/mike-lindblom/"
rel="author"
class="p-author h-card hcard url fn">Mike Lindblom</a>
...
</div>
</div>However, there are many pages where these rules fail. Some do not include any special author markup. For example, this page does not include any markup in the byline:

It also illustrates another challenge where the author is not a person’s name but rather an organization. Other examples along these lines are phrases like “Editor” or “News Staff.”
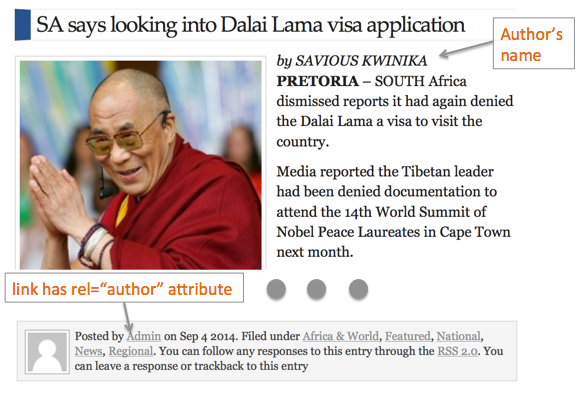
In other cases, the page markup is misleading. For example, this news page includes a byline without any markup and a link with rel="author" to “Admin” below the story:
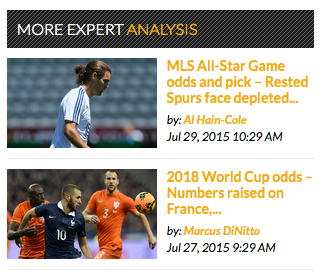
Pages with links to related content and many bylines also present a challenge to distinguish them from the main article byline:
Finally, some pages do not include any author, and our algorithm should gracefully handle these cases. Blog home pages and category pages are particularly tricky cases, since they often include many links and bylines on a single page but don’t have a single author.
Machine learning to the rescue!
Supervised machine learning provides a way to move beyond a rule-based system. We partnered with Spare5 to crowd source high quality labeled training data using their platform. Accurate labeled data was essential for training an excellent model, and Spare5 delivered. In our case, the training data includes the HTML with extracted author names.
Model overview
While it may be possible to train an end-to-end deep learning algorithm on the raw data, we decided to start with a conventional system with prescribed architecture and hand engineered features. This allowed us to quickly develop and ship an algorithm for the product launch.
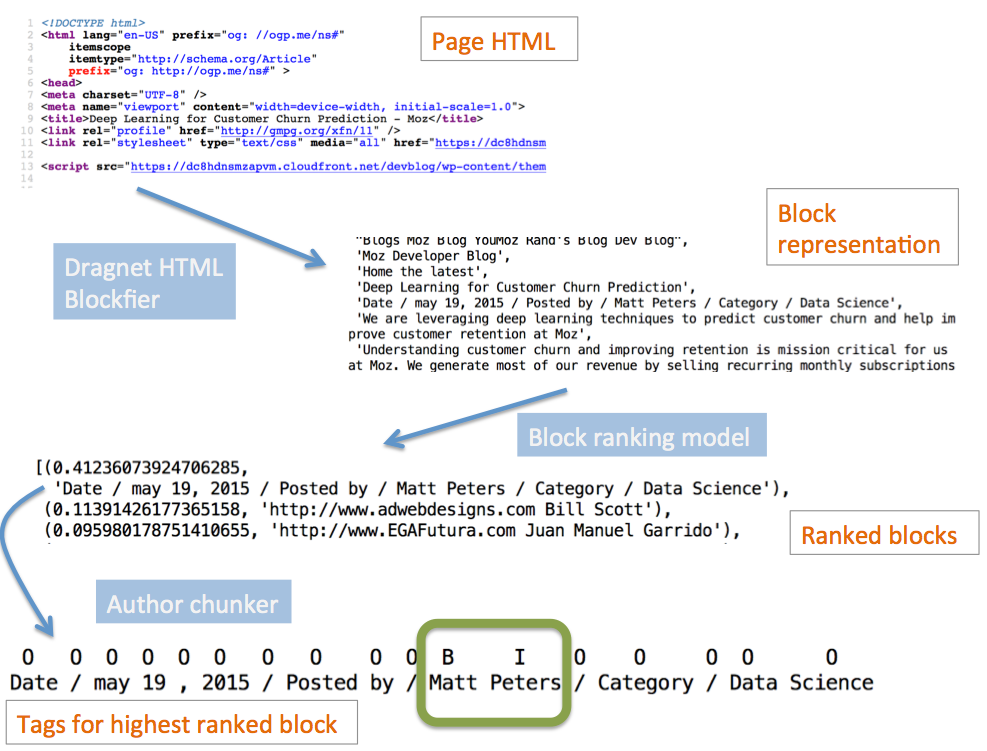
The above figure illustrates the model using a previous post on our blog as a case study. At a high level, the model processes a page with three main steps (working from top to bottom of the figure):
- Parsing the HTML into a list of small pieces
- Determining which piece contains the author
- Extracting the author tokens from the selected piece
The first step parses the HTML into a “block” representation using the parser in Dragnet, our content extraction algorithm. Each block is an individual page chunk separated by HTML tags used for visual markup like div, p, h1, etc. Our intuition is that, in most cases, the article byline will be a separate block and should be easy to distinguish from the rest of the page. This is the case in the example above. We decided to reuse the Dragnet parser since it is battle-tested having been in production at Moz for a few years, and can easily scale to tens to hundreds of millions of pages per day without a lot of hardware.
Next, we use a ranking model to determine which blocks are most likely to contain the author.
The final step runs a sequence chunker on the highest-ranked blocks to tag the author tokens.
Block model
The block model is a random forest classifier trained to predict the probability the block includes the author. We used several different types of features, including:
- Tokens in the block text
- Tokens in the block HTML tag attributes
- The HTML tags in the block
rel="author"and other markup inspired features
Overall, the block model performs fairly well. The following table lists the Precision@K on our test set, the percent of the highest-ranked K blocks that actually include an author. The top ranked block includes an author about 92% of the time, consistent with our intuition that author bylines are easy to identify in most cases.
| K | Precision |
|---|---|
| 1 | 0.923 |
| 2 | 0.940 |
| 3 | 0.964 |
Author chunker
The author chunker is a modified version of an averaged perceptron tagger to include features unique to web pages. It takes the highest-ranked blocks as input and returns IOB (In-Out-Begin) labels for each token, effectively splitting the text into author and non-author chunks. To make a prediction, the chunker uses these features, among others:
- Unigrams, bigrams and trigrams from the previous/next few tokens
- N-gram part-of-speech tags for the previous/next few tokens
- HTML tags preceding and following the token
- The previous predicted IOB tags
rel="author"and other markup inspired features
Overall, this component correctly chunks a block about 85.6% of the time in our test set. We will describe the details of our chunker in a future post.
Overall performance and benchmarks vs other implementations
The following table shows end-to-end accuracy of the final model and a few other benchmark implementations (see the notes at the end for details on how we computed these results). It includes Jay’s original prototype, the results from Alchemy API’s Authors Extraction endpoint and the authors from Newspaper, a popular Python web scraping library. We’d like to extend this list with additional APIs and libraries in the future. If you would like to see the comparisons from others, please let us know in the comments.
| Implementation | Overall accuracy |
|---|---|
| Final model | 80.5% |
| Jay’s prototype | 61.1% |
| Alchemy API | 54.5% |
| Newspaper | 44.1% |
Overall, the accuracy from our model is significantly higher than from other implementations. The machine learning approach approximately halves the error rate versus the rule-based prototype.
Since the results from our algorithm are prominently displayed in the UI, we also took care to minimize the “obvious” error rate to improve the user experience. There are three types of errors, with the first two “obvious” errors:
- The algorithm returns an author for a page without an author
- The algorithm returns the wrong author for a page with an author
- The algorithm returns no authors for a page with an author
In other words, we’d like to return “no author” unless we are reasonably confident that the extracted name it is correct. Our algorithm has an “obvious” error rate of 5.6% on the test vs rates exceeding 25% for all the other implementations.
Takeaways
We have implemented a state of the art web page author extraction algorithm that performs significantly better than other available solutions. This algorithm is integrated into Moz Content and will be available as a public API in the coming months. In the future, we plan to add additional components to extract more structured data from the web pages we crawl and process.
Notes on accuracy calculations
The reported accuracy is the end-to-end accuracy to return a list of authors, or an empty list if there are no authors. An extracted author list is only counted as correct if it matches the gold standard exactly (no “partial credit”). Multi-author lists are normalized by sorting both the gold standard and algorithm results before comparison. We also case normalize extracted authors to match our gold standard data.
Alchemy API returns a measure of confidence with the extracted author list. The table lists the accuracy including “not confident” results as authors since it resulted in a higher score than including “not confident” results as non-authors.
Note: this article was originally published on the Moz devblog.