We are leveraging deep learning techniques to predict customer churn and help improve customer retention at Moz.
Understanding customer churn and improving retention is mission critical for us at Moz. We generate most of our revenue by selling recurring monthly subscriptions to Moz Pro, similar to other software-as-a-service (SaaS) companies like Netflix. Accordingly, decreasing churn of existing customers can have a enormous impact on our overall revenue growth rate.
Recently, we (Data Science) have been collaborating with the Customer Success and Help teams to model churn and provide overall “qualification” scores for each customer. Recurrent Neural Networks (RNNs) provide state-of-the-art performance in a variety of natural language processing sequence modeling tasks such as language modeling and machine translation, so it’s natural to ask whether they are useful for modeling a time series of customer actions. This post explains our production RNN used to predict churn.
Business use case
The Customer Success team at Moz works 1:1 with our customers and provides support in a variety of ways, including:
- Onboarding new free trialers and checking in on older users throughout their life-cycle (via email and live chat)
- Offering in-app contextual suggestions about how to use our tools
- Trouble shooting, fielding account-related questions, and passing along feedback to our Product teams
As we scale as a business, we need an efficient way of doing outreach. Scores that quantify which level customers are at allow the Success team to better prioritize their energies. An earlier prototype version of these scores helped the team increase long-term retention rates 15% in an A/B test, and the features that supported this prototype provided a way for the team to strategically contact users based on their engagement with the product. It also provided a way to quantify the health of our acquisition funnel. As a result, we are optimistic that continued modeling investments will help move the needle further.
Customer lifecycle
Moz has a fairly standard SaaS business model with a 30-day free trial:
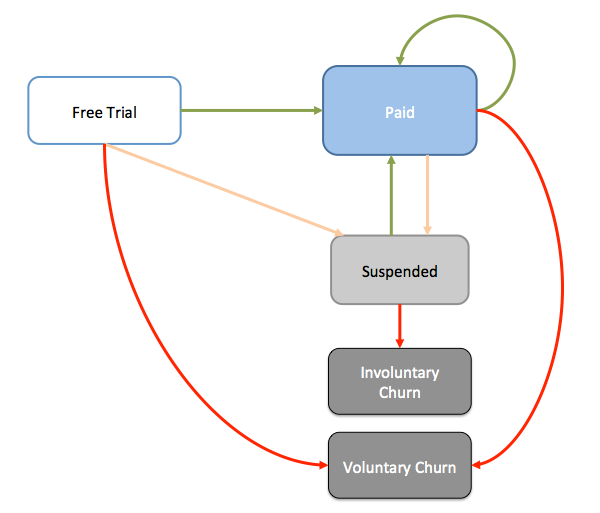
New customers sign up for a free trial, after which they convert to a monthly subscription. They may voluntarily cancel their subscription at any time through our site, at which point they are no longer a customer. If their credit card is declined during the monthly billing cycle, then they enter a “Suspended” state. If the customer updates their billing information they enter back into the “Paid” state; otherwise, they involuntarily churn after 18 days of suspension.
Our RNN models all components of this lifecycle: voluntarily churn and involuntarily churn, as well as free trial vesting.
Long term memory in customer behavior
Since we build a relationship with most of our customers over several months, it’s interesting to ask whether events that occur early in a customer’s life can have an impact on whether they cancel several months later. It turns out these long range dependencies do exist, so using a model that captures them is important for accurately modeling churn.
One example of this long-term dependency is involuntary churn. Our churn is roughly split 50-50 between involuntary and voluntary, so both are important for overall churn. Now, as customers mature in their lifecycle, suspended users are increasingly more likely to have had a prior suspension:
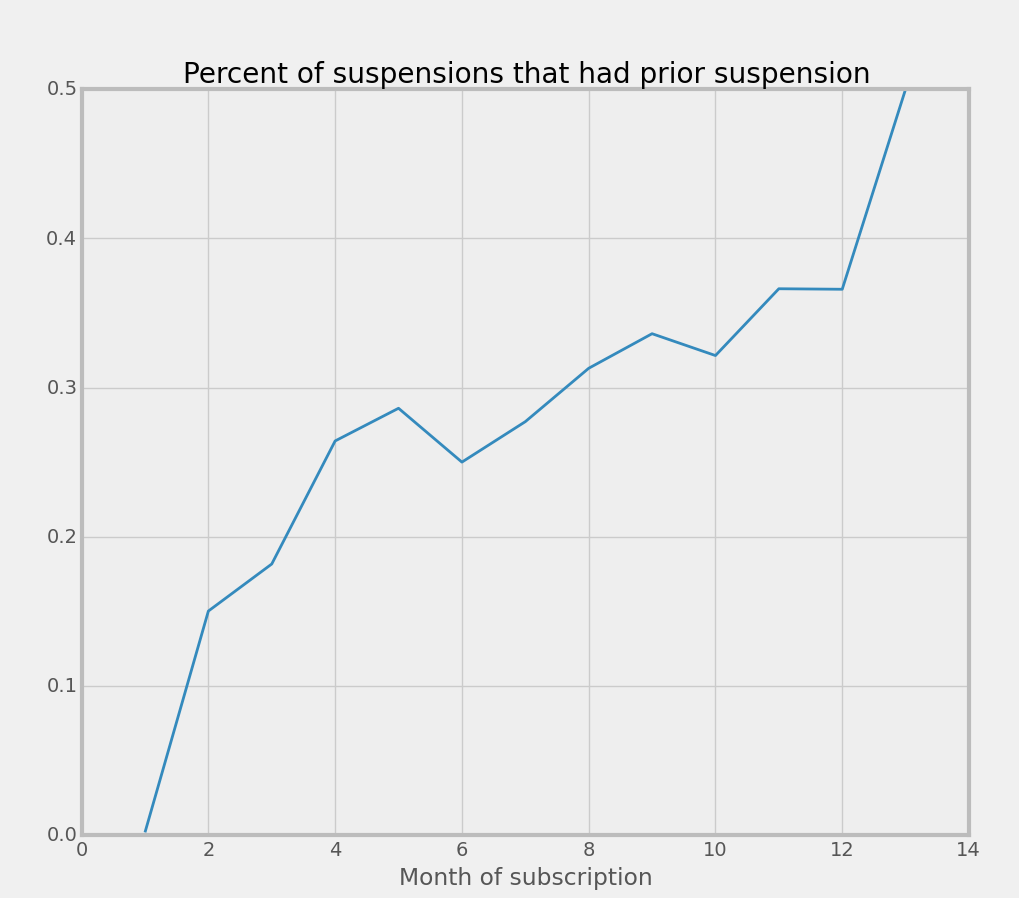
Therefore, knowledge of whether a customer has had a prior suspension is important for predicting future suspensions and involuntary churn.
The following histogram shows that the time lag between first and last suspension can be many months or more:
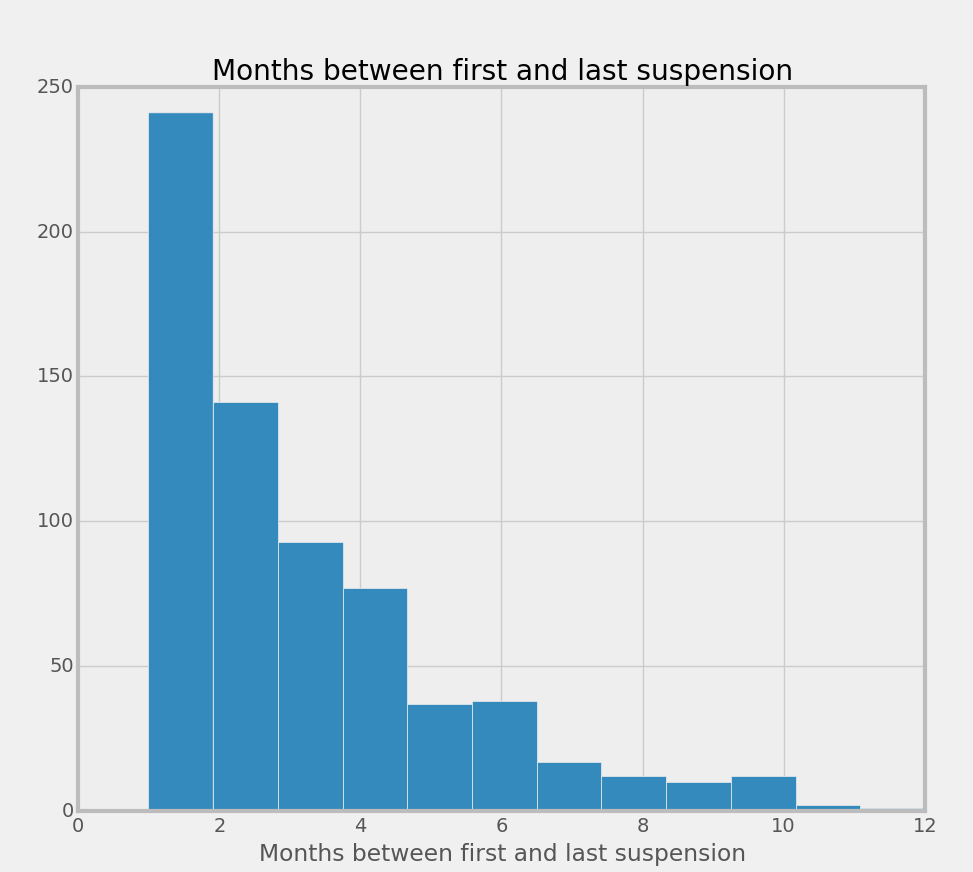
Note that censoring in the data under-counts the higher buckets, but we won’t worry about those details here. The salient point is that events early in a subscription can have impacts many months later.
Model architecture
RNNs are sequence models that take some observed input at a sequence of times and evolve a “hidden” state vector that is used to predict some output. At any point in the series, the hidden vector encodes all of the accumulated state at that point in the series. As a result, they can propagate long-term dependencies in the data through the hidden vector.
In our case, each customer lifecycle corresponds to a single time series. The input vector at each prediction point is the accumulated events and actions since the prior prediction (see following image). Word vectors at each position are the analogous input in a language model RNN.
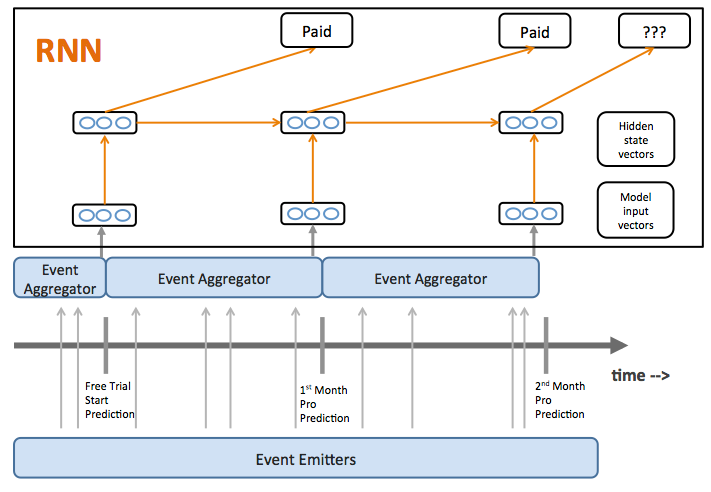
The model output at each month is the customer state one month in the future as one of three classes: still a customer, voluntarily churn, or involuntarily churn. The next word is the analogous output in a language model RNN.
Event emitters and aggregator
Our model uses a flexible event emitter/aggregator framework that enables a wide variety of inputs to be included in the model. Each event emitter sends many events to the aggregator, which then handles the details of how to accumulate them into input vectors to the model (see bottom of figure above).
Each event is abstracted as a (type, timestamp, value) tuple, so that the event emitter implementations are as flexible and simple as possible. A few examples of different events in our current model are:
- Click tracking:
('click on page X', '2015-05-15 14:22:16', 1) - Reactivating a subscription four days into a suspension:
('reactivate', '2015-05-14', 4)
This framework also allows us to easily include “demographic” features in our model. For example, user@company.com is more likely to be qualified then user@hotmail.com, as are repeat customers. We include these type of features by emitting events at the beginning of the lifecycle and relying on the model to propagate/decay them in later months as appropriate.
Model Performance
The following table compares the AUC (area under receiving operator curve) of our model on a variety of tasks vs. a logistic regression baseline. Each cell gives the Involuntary / Voluntary AUC scores for the particular model and cohort. Since we migrated to an improved analytics tracking system a few months ago, it was necessary to split all users into two cohorts due to a data discontinuity. Overall voluntary churn is a harder prediction task than involuntary churn, and since the average churn rate decreases significantly for seasoned customers, the 5 – 16 month cohort has lower AUC then the 1 – 4 month cohort.
| Cohort | Logistic | RNN |
|---|---|---|
| Months 1-4 | 0.86/0.78 | 0.87/0.79 |
| Months 5-16 | 0.78/0.56 | 0.82/0.61 |
AUC scores for various cohorts, model architectures and prediction tasks. Each cell contains the Involuntary / Voluntary performance.
The improvement in performance of the RNN is most pronounced in the seasoned cohort, as there is a long time period of accumulated user state that it can represent that the simpler logistic model cannot.
Model Details
(updated February 2016)
The model is in Python and leverages Theano. The original implementation used the abstractions in breze for different layer and model types, and climin for stochastic gradient descent. It used rectified linear units as the hidden layer with initialization as suggested in this paper. Subsequently, we replaced the vanilla RNN with a LSTM and moved to keras for the implementation and training. As we have different length time series for each customer, we first padded all input vectors to a fixed length, then took care to mask out the padded values when computing the softmax loss output. Padding the input vectors to a fixed size allows use of efficient BLAS linear algebra libraries.
Summary and next steps
We have implemented a recurrent neural network for customer churn prediction and found it to make significantly better predictions then a logistic regression baseline. It is built on a flexible event emitter/aggregator framework that allows a wide variety of features to be included in the model and added over time.
Note: this article was originally published on the Moz devblog.